Enterprise automation initiatives rarely fail because the algorithm is weak. They fail because the data underneath is still trapped in legacy, functional silos. Fix the foundation first, and the double-digit returns follow.
As organizations accelerate automation and AI adoption, many discover that the biggest obstacle is not technology it is data quality. Data remediation establishes consistent, trusted, and governed data across enterprise systems, enabling automation to operate with accuracy, reliability, and measurable business impact.
What Is Data Remediation?
Data remediation is the process of improving data quality by standardizing business definitions, resolving inconsistencies, correcting errors, and governing critical enterprise data before it is used by automation, analytics, or AI systems.
Without data remediation, automation inherits fragmented data, resulting in manual exceptions, inconsistent decisions, and lower return on investment.
Key Takeaways
- Enterprise automation often fails because of poor data quality rather than weak algorithms.
- Functional data silos create conflicting business definitions across systems.
- Data remediation creates a trusted foundation for automation and AI.
- Consistent, governed data reduces manual intervention and improves straight-through processing.
- Organizations that remediate data before automating achieve higher automation ROI.
The Quiet Failure
Most automation programs do not fail loudly.
They fail quietly.
A pilot that worked beautifully in a demo never quite survives contact with real, day-to-day data, and six months in the team is still babysitting the very process the automation was meant to remove.
When this happens, the first instinct is to question the algorithm.
We have felt that reflex too: we have arrived on engagements expecting to tune a model or add another layer of integration logic, only to find the automation was sound.
What it was standing on was not.
Why Poor Data Quality Causes Automation Failures
The real bottleneck sits upstream, in the core data architecture.
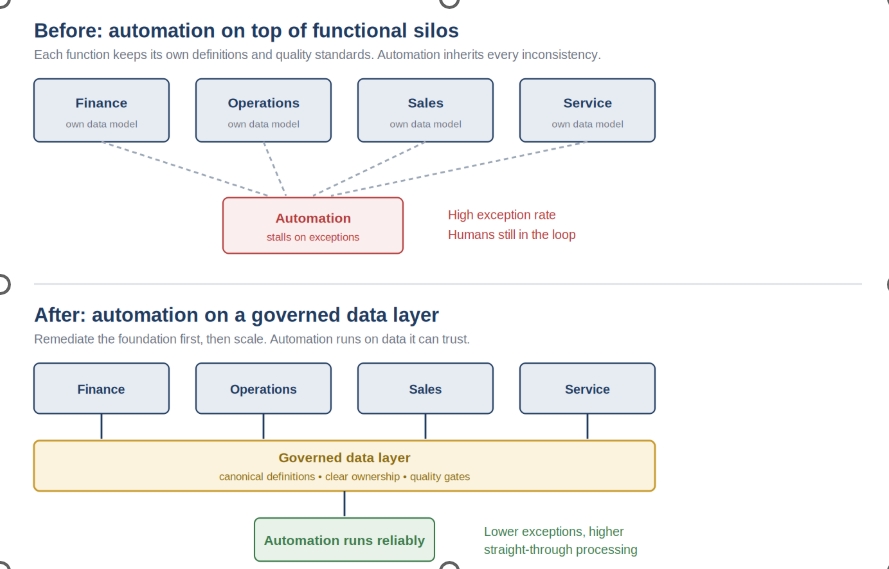
In most established organizations, data is still organized around functional silos. Finance, operations, sales, and service each own their own systems, and each has quietly evolved its own definitions, formats, and tolerance for “good enough” quality.
A customer is one entity in the CRM, another in billing, and a third in the support desk.
None of this matters much when people are in the loop, because they reconcile the differences instinctively.
Automation cannot.
The moment a workflow crosses a functional boundary, it inherits the inconsistencies those silos have accumulated, and the model is asked to reason over a foundation that contradicts itself.
You are not removing manual effort you are relocating it, from doing the task to correcting the exceptions automation cannot resolve on its own.
A Real-World Example: Data Remediation in Digital Lending
A mid-sized digital lender set out to automate loan decisioning and borrower communications.
On paper, it was a clean problem for automation.
In practice, a borrower’s details lived in one shape in the origination platform, another in the servicing system, another in the credit bureau feed, and another again in the CRM.
Even fundamental concepts such as “applicant,” “active loan,” and “delinquent” meant subtly different things in each system.
The decisioning engine routed a large share of applications to manual review because the inputs disagreed, and collections reminders went to borrowers who had already paid.
The instinct was to retrain the model.
The actual fault line was the data.
The CRM, the Loan Origination System, the Credit Bureaus, and the Decision Engine—four systems that never agreed on what a borrower or a loan is.
Data Remediation Before Enterprise Automation
The way out is less glamorous than a new model—and far more durable.
Treat data remediation as a precondition for automation, not as cleanup you get to later.
Conceptually, this means three shifts.
Establish Canonical Business Definitions
Agree on canonical definitions so the same business concept is not represented differently across systems.
Assign Clear Data Ownership
Assign ownership for each core data domain so quality has an accountable home rather than falling between teams.
Introduce Data Quality Gates
Place lightweight quality gates where data enters and crosses systems, ensuring problems are identified at their source rather than surfacing later as automation failures.
This is a way of thinking, not a fixed recipe.
The right sequence depends on where an organization’s fragmentation is most expensive, and that is a judgment we make with a client, not a template we apply.
How Data Remediation Improves Automation ROI
Return to the lender.
Once a borrower and a loan are defined once, owned clearly, and validated at the point of entry, the automation that had stalled starts to behave.
Exception rates fall because the inputs stop contradicting each other.
Straight-through decisioning rises because workflows no longer pause to ask which version of the truth to believe.
n engagements where we have led with remediation, the same automation that had been written off began clearing work end to end, and the return on the overall initiative moved into double digits—not because the technology got smarter, but because it was finally standing on solid ground.
The Takeaway
The takeaway is simple to state and uncomfortable to act on.
Before you fund the next automation initiative, look honestly at the data beneath it.
If your core entities cannot agree on what they are across systems, no algorithm will resolve that for you.
Remediate the foundation first, and automation stops being a science experiment and starts being an investment that pays back.
That is usually where the real return is won or lost.
Frequently Asked Questions
What is data remediation?
Data remediation is the process of improving data quality by correcting inconsistencies, standardizing business definitions, and governing enterprise data before it is used by automation or AI systems.
Why is data remediation important for enterprise automation?
Enterprise automation depends on accurate and consistent data. Without data remediation, automation inherits fragmented information, resulting in manual exceptions, inconsistent decisions, and lower business value.
How do data silos affect automation?
Data silos create conflicting definitions and inconsistent records across systems. When automation relies on these disconnected data sources, workflows generate more exceptions and require additional manual intervention.
How does data remediation improve automation ROI?
Data remediation improves automation ROI by reducing manual reconciliation, increasing straight-through processing, improving decision accuracy, and enabling automation initiatives to deliver measurable business outcomes.
What is the relationship between data remediation and AI readiness?
AI systems perform best when they are trained and operated on trusted, high-quality data. Data remediation creates the reliable data foundation needed for scalable AI and enterprise automation initiatives.